
في أكتوبر 2024 ، أعلننا التوافر العام للمسح السري Copilot، الاستفادة من الذكاء الاصطناعى للكشف عن كلمات المرور العامة في قواعد الكود للمستخدمين. يصف هذا المنشور كيف يعمل Secret Secret Secret تحت الغطاء ، والتحديات التي واجهناها عند تطويرها ، والإطار الذي نستخدمه للاختبار والتكرار.
ما هو المسح السري Copilot؟
المسح السري Copilot هو ميزة GitHub Secret Protection، الذي يحمي ملايين المستودعات على Github من خلال اكتشاف مئات أنواع الأنماط من خلال برنامج شريكنا. تعتبر دقة هذه الاكتشافات أمرًا بالغ الأهمية لفرق الأمان والمطورين عند التعامل مع تنبيهات الأمن. تاريخياً ، اعتمد نهج الكشف الخاص بنا على التعبيرات العادية ، والتي تعد طريقة فعالة لتحديد الأسرار بتنسيقات صارمة ومقدمة. ومع ذلك ، فإن هذه الطريقة تكافح مع الهياكل الدقيقة والمتنوعة من كلمات المرور العامة ، وغالبًا ما تولد ضوضاء مفرطة لفرق الأمان والمطورين.
نكتشف الآن كلمات مرور عامة مع Github Copilot ، باستخدام الذكاء الاصطناعى لتحليل السياق – مثل استخدام وموقع سر محتمل – للحد من الضوضاء وتقديم التنبيهات ذات الصلة التي تعتبر حاسمة لصحة وأمن مستودعاتك.
إن الوصول إلى النقطة التي كنا على ثقة في دقة كلمة المرور الخاصة بنا كانت رحلة عبر العديد من حالات الاختبار والتكرار الفوري وتغيير النماذج. دعنا نغوص لاستكشاف ما تعلمناه على طول الطريق ومعرفة إلى أين نحن ذاهبون.
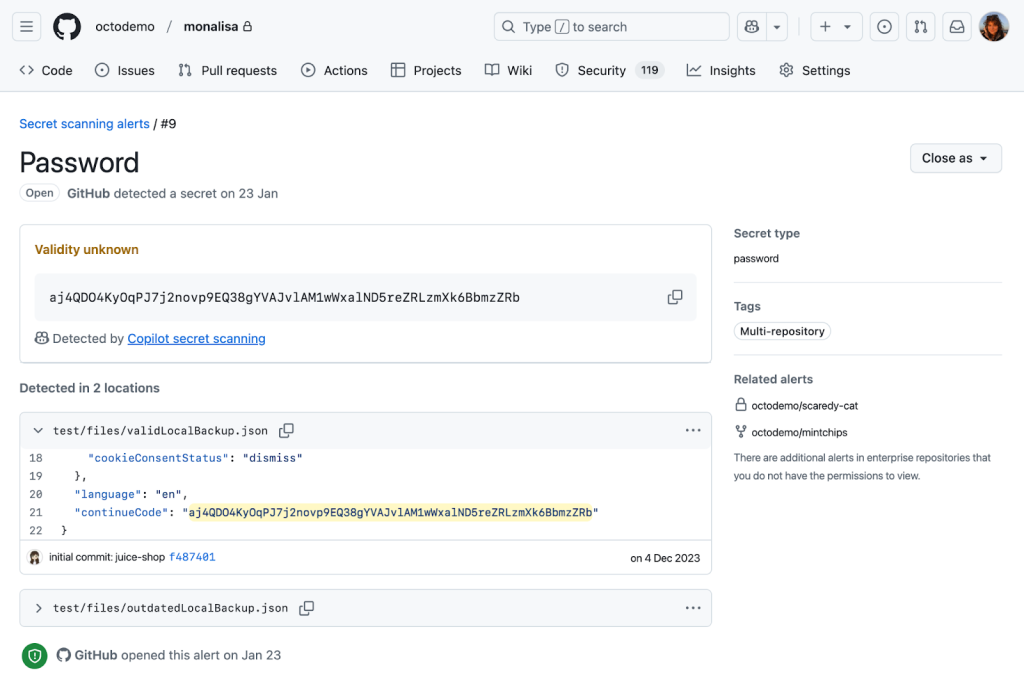
أبرزت المعاينة الخاصة مشكلة في وقت مبكر: أنواع الملفات غير التقليدية
في قلب المسح السري Copilot ، يكمن طلب إلى نموذج لغة كبير (LLM) ، يتم التعبير عنه من خلال مطالبة LLM التي تتكون من:
- معلومات عامة حول نوع الضعف ، في هذه الحالة كلمات مرور.
- موقع رمز المصدر ومحتويات الملف حيث نعتقد أن الضعف قد توجد.
- مواصفات تنسيق JSON صارمة لإخراج النموذج ، للسماح للمعالجة الآلية.
استخدم التكرار الأول للمطالبة تقنية الطرافة القليلة ، والتي توفر LLM مع إدخال مثال ومخرجات لإظهار كيفية تنفيذ المهمة. أردنا أن يقوم نموذج فعال للموارد بإدارة الاكتشافات على نطاق واسع وهبط على GPT-3.5-Turbo. في موازاة ذلك ، قمنا بتطوير إطار تقييم أساسي للإنترنت ، بما في ذلك حالات الاختبار المنسقة يدويًا مع كل من النتائج الإيجابية والسلبية ، لمساعدتنا على التحقق من أن نهجنا كان سليمًا قبل نشره على العملاء.
لقد نشرنا هذا التكرار الأول للمشاركين في المعاينة الخاصة لدينا ولاحظنا مشكلة على الفور. على الرغم من أنها نجحت بشكل جيد في تحديد بيانات الاعتماد في تقييمنا دون اتصال ، إلا أنها ستفشل بشكل مذهل في بعض مستودعات العملاء. واجه النموذج صعوبة في تفسير أنواع الملفات والهياكل التي لا تُرى عادة في لغات الترميز التقليدية والأنماط التي تتدرب عليها LLMS.
كشفت هذه التجربة عن تعقيد المشكلة والطبيعة المحدودة لـ LLMs. كان علينا إعادة تقييم نهجنا.
الطريق إلى المعاينة العامة: تحسين التقييم غير المتصلة بالإنترنت والطالب
استجابةً لهذه النتائج الأولية ، قمنا بتحسين إطار التقييم غير المتصلة ببعض الطرق الرئيسية. أولاً ، أضفنا تقارير من المشاركين المعاينة الخاصة لزيادة تنوع حالات الاختبار الخاصة بنا. بعد ذلك ، قمنا بتحسين الإطار حتى نتمكن من تحديد وتحليل الانحرافات الناتجة عن النموذج أو التغييرات الفورية. هذا سمح لنا أن نرى بشكل أفضل تأثير تخصيص الخطوات المختلفة في استراتيجيتنا المطلوبة. أخيرًا ، استفدنا من فريق أمان كود جيثب عمليات التقييم لإنشاء خط أنابيب لجمع البيانات ، واستخدم GPT-4 لإنشاء حالات الاختبار الخاصة بنا بناءً على تعلم من تنبيهات المسح السرية الحالية في مستودعات المصادر المفتوحة.
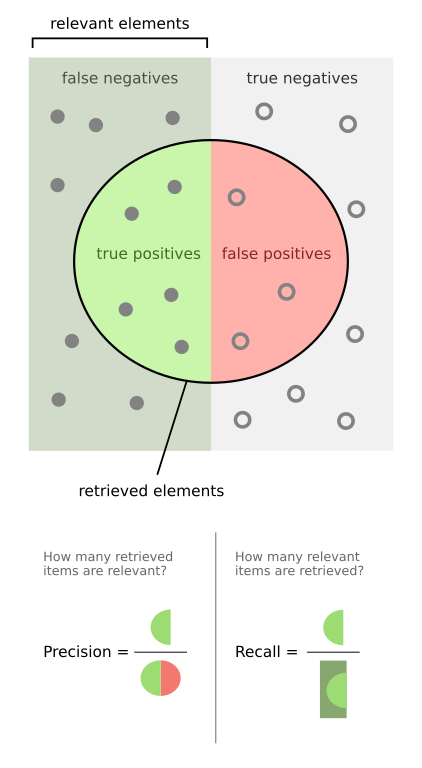
هذا التقييم غير المتصلة بالإنترنت وأعطانا اتساعنا اللازم لقياس كل من الدقة والاستدعاء. الدقة هي القدرة على إيجاد أسرار أكثر دقة ، مع مخاوف من المعدل الإيجابي الخاطئ ، في حين أن الاستدعاء هو القدرة على العثور على أسرار أكثر موثوقية ، مع مخاوف من المعدل السلبي الخاطئ.
{kind=link}
من هنا ، أجرينا سلسلة من التجارب لتقييم جودة الكشف:
- ماذا لو جربنا نموذجًا مختلفًا؟
- ماذا لو قمنا بتشغيل المطالبة عدة مرات ودمجنا بطريقة ما الاستجابات؟
- ماذا لو قمنا بتشغيل مطالبين مختلفين على نموذجين مختلفين في التسلسل؟
- كيف يمكننا التعامل بشكل أفضل مع الطبيعة غير المحددة لاستجابات LLM؟
وبشكل أكثر تحديدًا ، بدأنا في تجربة بعض الآليات المختلفة لتحسين اكتشافنا مع LLM.
لقد حاولنا التصويت (طرح السؤال نفسه على نفس الوقت عدة مرات) ، مما سمح باستجابات أكثر حتمية ولكن لم يكن له أي تأثير مادي على دقتنا.
لقد حاولنا أيضًا استخدام نموذج أكبر (GPT-4) المدربين على مجموعة أكبر من المعلمات كماسح ضوئي تأكيد ، للتحقق من دقة المرشحين الذين تم العثور عليهم بواسطة GPT-3.5-TURBO. وقد ساعد ذلك في تحسين الدقة دون تقليل استدعاءنا ، ولكنه كان أيضًا أكثر كثافة في الموارد.
لقد جربنا أيضًا بعض الاستراتيجيات المختلفة للطلاء ، مثل Fill-in-Middle ، و Zero-Shot ، وسلسلة الفكرة. لقد انتهى الأمر بالتعاون مع زملائنا في Microsoft واستخدمنا تقنية Metareflection، وهي تقنية تعليمية جديدة غير متصلة بالإنترنت تتيح التعلم التجريبي من التجارب السابقة للتوصل إلى سلسلة من الفكر المختلط (COT) ومطالبة قليلة من الدقة التي تحسن عقوبة صغيرة في الاستدعاء.
انتهى بنا المطاف في النهاية باستخدام مجموعة من جميع هذه التقنيات ونقلنا المسح السري Copilot إلى معاينة عامة ، وفتحها على نطاق واسع لجميع عملاء GitHub Secret Protection. هذا يقودنا إلى عقولنا القادمة: النطاق.
تحجيم القدرة لمعاينة عامة
المسح السري ليس فقط يقوم بمسح دفعات GIT الواردة ، ولكن أيضًا تاريخ GIT بالكامل على جميع الفروع. مع كل عميل جديد ، تزيد الموارد اللازمة خطيًا. بدلاً من مجرد توسيع سعة LLM ، ركزنا على تحقيق التوازن الأكثر فعالية بين القيمة والتكلفة لضمان الأداء الأمثل والكفاءة. قبل معالجة كيفية إدارة الموارد ، حاولنا إيجاد طرق لتقليل استخدام الموارد نفسه بواسطة:
- تحديد واستبعاد فئة من التغييرات من المسح (مثل ملفات الوسائط أو ملفات اللغة التي تحتوي على “اختبار” ، “Mock” ، أو “Spec” في FilePath) ، لأننا توقعنا ألا تحتوي على بيانات اعتماد أو أنها ستكون غير مفهومة للنموذج.
- تجربة النماذج الأحدث ، مثل GPT-4-TURBO و GPT-4O-MINI ، والتي كان من المتوقع أن تكون أقل كثافة للموارد دون المساومة على الأداء والكمون.
- تجربة نوافذ سياق مختلفة للعثور على الموارد التي خفضت الموارد دون زيادة كبيرة في زمن انتقال LLM للاستجابة لاستفساراتنا.
- إجراء تحسينات على كيفية تفسير المحتوى الذي نريد مسحه ، بما في ذلك الاحتفاظ ببعض ذاكرة الرمز المميزات السابقة أثناء معالجة أجزاء جديدة من الملف.
في حين أن بعض هذه الجهود أثبتت أنها مثمرة ، مثل الحد من المحتوى الذي قمنا بمسحه ضوئيًا ، كانت الجهود الأخرى أقل فعالية. على سبيل المثال ، لم يكن لتحويل المحتوى إلى قطع أصغر تأثير كبير ، أثناء استخدام نموذج أكثر قوة.
في نهاية المطاف ، جاء التغيير الأكثر تأثيرًا من إنشاء نظام إدارة لطلب عبء العمل الذي سمح لنا بزيادة وسعة LLM بشكل أقصى مع مجموعة متنوعة من أعباء العمل المختلفة التي نديرها أثناء عمليات الفحص.
في بناء النظام ، لاحظنا مشكلة أساسية تحتاج إلى معالجة في إدارة طاقتنا: تعيين حدود أسعار محددة لأعباء العمل الفردية (مثل مسح GIT الواردة أو مسح التاريخ الكامل) كان دون المستوى الأمثل. نظرًا لأن كل عبء عمل مرتبط بأنماط مرور محددة – فإن GIT يرتبط ، على سبيل المثال ، يميل إلى الارتباط بساعات العمل ، في حين أن المسح الكامل في سجل المرتبط بأحداث منفصلة مثل مدير الأمن أو المسؤول الذي يمكّن هذه الميزة على منظمة جديدة – كان من السهل الهبوط في موقف يمكن أن يدير فيه عبء العمل الفردي حدودًا في المعدل في سياقها العملي المتاح بموارد إضافية غير مستخدمة.
لقد استخلصنا من الحلول الموجودة في هذا المجال ، مثل بواب، جيثب الفرامل، والعديد من الخوارزميات ذات الصلة المرجحة الأخرى المرجحة. لقد توصلنا إلى خوارزمية تتيح لنا وضع مجموعة من الحدود لكل عبء عمل ، ومنع عبء العمل من LLM الساحقة تمامًا ، مع السماح لها بالاستفادة من الموارد من أعباء العمل الأخرى غير المستخدمة في الوقت الحالي. كانت هذه الاستراتيجية فعالة للغاية في زيادة الاستخدام إلى الحد الأقصى لدرجة أننا انتهينا من استخدامها في الداخل Copilot Autofix و الحملات الأمنية أيضًا.
مرآة اختبار طريقنا إلى التوافر العام
كان تحقيق الثقة في جودة الكشف أمرًا بالغ الأهمية لنقل المسح السري لـ Copilot إلى توافر عام. قمنا بتنفيذ إطار اختبار المرآة الذي قام بإجراء تغييرات سريعة وتصفيةنا ضد مجموعة فرعية من المستودعات التي شاركت في معاينتنا العامة. لقد سمح لنا تنشيط هذه المستودعات بأحدث التحسينات لدينا بتقييم التغيير في أحجام التنبيه الحقيقية والقرارات الإيجابية الخاطئة ، دون التأثير على المستخدمين.
لقد وجدنا انخفاضًا كبيرًا في الاكتشافات والإيجابيات الخاطئة مع عدد قليل جدًا من كلمات المرور الحقيقية المفقودة. في بعض الحالات ، رأينا أ انخفاض بنسبة 94 ٪ في إيجابيات كاذبة عبر المنظمات! أشارت هذه المقارنة قبل وبعد أن جميع التغييرات المختلفة التي أجريناها أثناء المعاينة الخاصة والعام أدت إلى زيادة الدقة دون التضحية بالاستدعاء ، وأننا على استعداد لتوفير آلية اكتشاف موثوقة وفعالة لجميع عملاء حماية GitHub Secret.
دروس للمستقبل
يكتشف Copilot Secret Scarning الآن كلمات المرور على ما يقرب من 35 ٪ من جميع مستودعات حماية Secret Github. نستمر في مراقبة الأداء وتطبيق الدروس المستفادة مع الاستفادة من الأدوات التي أنشأناها على طول الطريق:
- التركيز على الدقة: تحتاج فرق الأمن والتطوير إلى تنبيهات دقيقة وقابلة للتنفيذ دون الضوضاء – وهذا هو هدفنا الأساسي دائمًا.
- بما في ذلك حالات الاختبار المتنوعة: نستمر في دمج أمثلة بناءً على التعلم من ملاحظات العملاء في سرير الاختبار الخاص بنا أثناء صقل قدرات الكشف الخاصة بنا.
- إدارة الموارد الفعالة: نحتاج دائمًا إلى موازنة قابلية التوسع مع الأداء.
- الابتكار التعاوني: يساعدنا الشراكة مع فرق GitHub و Microsoft الأخرى في دفع حدود ما يمكن أن يحققه Copilot.
تتم مشاركة هذه التعلم أيضًا عبر Copilot Autofix ، والتي تستمر في توسيع نطاق تغطية تنبيهات مسح الكود وتساعد على تطوير تنبيهات مسح الكود بسرعة.
منذ إطلاق التوفر العام لدينا ، تم تضمين التمكين للمسح السري Copilot في تكوينات الأمان ، مما يسمح لك بالتحكم في المستودعات التي تكتشف الأسرار عبر المؤسسات أو مؤسستك. نحن نكرس للتحسين المستمر من خلال المراقبة المستمرة واختبار المرآة وتحسين النهج بناءً على ملاحظات العملاء واتجاهات الكشف. يعد Copilot Secret Scarning مكونًا مهمًا لأمان التطبيق القوي وسيتطور لتلبية الاحتياجات الديناميكية لمستخدمينا.
المسح السري Copilot هو ميزة GitHub Secret Protection، الذي يوفر حلولًا جاهزة للمؤسسات لمنع التعرض السري العرضي في مستودعاتك. GitHub Secret Protection متاح للشراء ابتداء من 1 أبريل 2025.
كتبه


اترك تعليقاً