
تمديد وضع علامة الذاكرة (MTE) هي ميزة سلامة الذاكرة المتقدمة التي تهدف إلى جعل نقاط الضعف للفساد للذاكرة من المستحيل استغلالها تقريبًا. ولكن لا يوجد أي تخفيف من أي وقت مضى محكمة الإغلاق – خاصة في رمز النواة الذي يعالج الذاكرة على مستوى منخفض.
في العام الماضي ، أنا كتب حول CVE-2023-6241 ، وهو ضعف في برنامج تشغيل GPU Mali’s Mali ، والذي مكن من تطبيق Android غير موثوق به لتجاوز MTE واكتساب تنفيذ رمز النواة التعسفي. في هذا المنشور ، سأمشي عبر CVE-2025-0072: ثغرة أمنية تم تصحيحها حديثًا وجدت أيضًا في برنامج تشغيل GPU Mali’s Arm. مثل التطبيق السابق ، فإنه يمكّن تطبيق Android الضار لتجاوز MTE واكتساب تنفيذ رمز النواة التعسفي.
لقد أبلغت عن القضية التي يجب تسليحها في 12 ديسمبر 2024. تم إصلاحه في إصدار برنامج تشغيل Mali R54P0، الذي تم إصداره علنًا في 2 مايو 2025 ، وشملته في Android’s مايو 2025 تحديث الأمن. تؤثر الثغرة الأمنية على الأجهزة ذات وحدة معالجة الرسومات الجديدة للذراعين التي تستخدم واجهة دفق الأوامر (CSF) الهندسة المعمارية ، مثل سلسلة Google Pixel 7 و 8 و 9. لقد طورت واختبرت الاستغلال على بكسل 8 مع تمكين kernel MTE ، وأعتقد أنه ينبغي أن يعمل على 7 و 9 وكذلك مع التعديلات البسيطة.
ما يلي هو الغوص العميق في كيفية عمل طوابير CSF ، والخطوات التي استخدمتها لاستغلال هذا الخطأ ، وكيف يتجاوز في النهاية حماية MTE لتحقيق تنفيذ رمز النواة.
كيف تعمل طوابير CSF وكيف تصبح خطرة
Arm Mali GPU مع ميزة CSF يتواصل مع تطبيقات Userland من خلال قوائم قوائم الأوامر ، التي تم تنفيذها في برنامج التشغيل AS kbase_queue أشياء. يتم إنشاء قوائم الانتظار باستخدام KBASE_IOCTL_CS_QUEUE_REGISTER ioctl. لاستخدام kbase_queue الذي تم إنشاؤه ، يجب أن يكون أولاً ملزمًا بـ kbase_queue_group، الذي تم إنشاؤه مع KBASE_IOCTL_CS_QUEUE_GROUP_CREATE ioctl. أ kbase_queue يمكن أن تكون ملزمة بـ kbase_queue_group مع KBASE_IOCTL_CS_QUEUE_BIND ioctl. عند ربط أ kbase_queue إلى kbase_queue_group، يتم إنشاء مقبض من get_user_pages_mmap_handle وعاد إلى تطبيق المستخدم.
int kbase_csf_queue_bind(struct kbase_context *kctx, union kbase_ioctl_cs_queue_bind *bind)
{
...
group = find_queue_group(kctx, bind->in.group_handle);
queue = find_queue(kctx, bind->in.buffer_gpu_addr);
…
ret = get_user_pages_mmap_handle(kctx, queue);
if (ret)
goto out;
bind->out.mmap_handle = queue->handle;
group->bound_queues(bind->in.csi_index) = queue;
queue->group = group;
queue->group_priority = group->priority;
queue->csi_index = (s8)bind->in.csi_index;
queue->bind_state = KBASE_CSF_QUEUE_BIND_IN_PROGRESS;
out:
rt_mutex_unlock(&kctx->csf.lock);
return ret;
}بالإضافة إلى ذلك ، يتم تخزين المراجع المتبادلة بين kbase_queue_group و queue. لاحظ أنه عندما تنتهي المكالمة ، queue->bind_state تم تعيينه على KBASE_CSF_QUEUE_BIND_IN_PROGRESS، مما يشير إلى أن الربط لم يكتمل. لإكمال الربط ، يجب على تطبيق المستخدم الاتصال mmap مع المقبض الذي تم إرجاعه من ioctl كما إزاحة الملف. هذا mmap يتم التعامل مع المكالمة من قبل kbase_csf_cpu_mmap_user_io_pagesالذي يخصص الذاكرة GPU عبر kbase_csf_alloc_command_stream_user_pages وتخطيطها إلى مساحة المستخدم.
int kbase_csf_alloc_command_stream_user_pages(struct kbase_context *kctx, struct kbase_queue *queue)
{
struct kbase_device *kbdev = kctx->kbdev;
int ret;
lockdep_assert_held(&kctx->csf.lock);
ret = kbase_mem_pool_alloc_pages(&kctx->mem_pools.small(KBASE_MEM_GROUP_CSF_IO),
KBASEP_NUM_CS_USER_IO_PAGES, queue->phys, false, //<------ 1.
kctx->task);
...
ret = kernel_map_user_io_pages(kctx, queue);
...
get_queue(queue);
queue->bind_state = KBASE_CSF_QUEUE_BOUND;
mutex_unlock(&kbdev->csf.reg_lock);
return 0;
...
}في 1. في المقتطف أعلاه ، kbase_mem_pool_alloc_pages يتم استدعاؤه لتخصيص صفحات الذاكرة من تجمع ذاكرة GPU ، ثم يتم تخزين عناوينه في queue->phys مجال. ثم يتم تعيين هذه الصفحات إلى مساحة المستخدم و bind_state تم ضبط قائمة الانتظار على KBASE_CSF_QUEUE_BOUND. يتم تحرير هذه الصفحات فقط عندما تكون منطقة MMEPT غير محفوظة من مساحة المستخدم. في هذه الحالة ، kbase_csf_free_command_stream_user_pages يتم استدعاؤه لتحرير الصفحات عبر kbase_mem_pool_free_pages.
void kbase_csf_free_command_stream_user_pages(struct kbase_context *kctx, struct kbase_queue *queue)
{
kernel_unmap_user_io_pages(kctx, queue);
kbase_mem_pool_free_pages(&kctx->mem_pools.small(KBASE_MEM_GROUP_CSF_IO),
KBASEP_NUM_CS_USER_IO_PAGES, queue->phys, true, false);
...
}هذا يحرر الصفحات المخزنة في queue->phys، ولأن هذا يحدث فقط عندما تكون الصفحات غير محددة من مساحة المستخدم ، فإنها تمنع الوصول إلى الصفحات بعد تحريرها.
فكرة استغلال
يبدأ الجزء المثير للاهتمام عندما نسأل: ماذا يحدث إذا استطعنا التعديل queue->phys بعد تعيينهم في مساحة المستخدم. على سبيل المثال ، إذا كان بإمكاني التشغيل kbase_csf_alloc_command_user_pages مرة أخرى للكتابة فوق صفحات جديدة إلى queue->phys، وقم بتخطيطها إلى مساحة المستخدم ثم قم بإلغاء تحديد المنطقة التي تم تعيينها مسبقًا ، kbase_csf_free_command_stream_user_pages سيتم استدعاؤه لتحرير الصفحات في queue->phys. ومع ذلك ، لأن queue->phys تتم كتابةها الآن من خلال الصفحات المخصصة حديثًا ، انتهى بي الأمر في موقف حيث أقوم بتحرير الصفحات الجديدة أثناء إلغاء تشكيل منطقة قديمة:
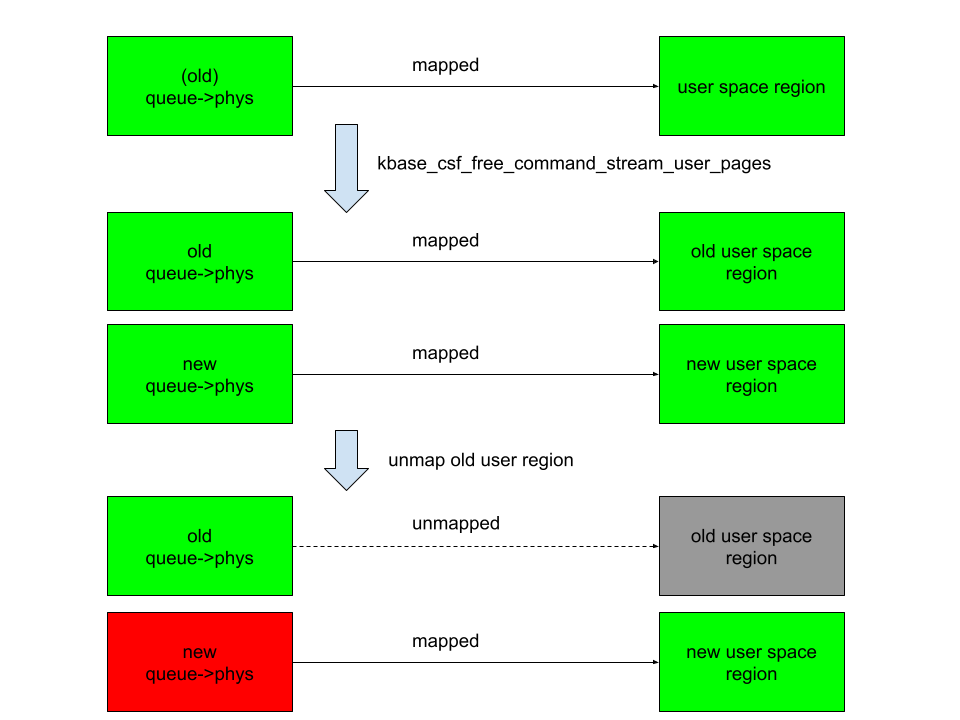
في الشكل أعلاه ، تكون الأعمدة اليمنى عبارة عن تعيينات في مساحة المستخدم ، يتم تعيين المستطيلات الخضراء ، في حين أن الأعمدة الرمادية غير محفوظة. العمود الأيسر يدعم الصفحات المخزنة في queue->phys. الجديد queue->phys هي صفحات مخزنة حاليا في queue->phys، بينما قديم queue->phys هي الصفحات التي يتم تخزينها مسبقًا ولكن يتم استبدالها بالمسلسلات الجديدة. يشير الأخضر إلى أن الصفحات على قيد الحياة ، بينما تشير Red إلى تحريرها. بعد الكتابة queue->phys وإلغاء تشكيل المنطقة القديمة ، الجديدة queue->phys يتم تحريرها بدلاً من ذلك ، بينما لا تزال تم تعيينها إلى منطقة المستخدم الجديدة. هذا يعني أن مساحة المستخدم ستتمكن من الوصول إلى الجديد المحرر queue->phys الصفحات. هذا يمنحني ثم ضعف استخدام الصفحة بعد خالية من الخالية.
الضعف
لذلك دعونا نلقي نظرة على كيفية تحقيق هذا الموقف. أول شيء واضح هو تجربته هو معرفة ما إذا كان بإمكاني ربط أ kbase_queue عدة مرات باستخدام KBASE_IOCTL_CS_QUEUE_BIND ioctl. هذا ، ومع ذلك ، غير ممكن لأن ال queue->group يتم فحص الحقل قبل الربط:
int kbase_csf_queue_bind(struct kbase_context *kctx, union kbase_ioctl_cs_queue_bind *bind)
{
...
if (queue->group || group->bound_queues(bind->in.csi_index))
goto out;
...
}بعد أ kbase_queue ملزم ، لها queue->group تم تعيينه على kbase_queue_group الذي يرتبط به ، والذي يمنع kbase_queue من الربط مرة أخرى. علاوة على ذلك ، مرة واحدة أ kbase_queue ملزم ، لا يمكن أن يكون غير مبين عبر أي ioctl. يمكن إنهاءها مع KBASE_IOCTL_CS_QUEUE_TERMINATE، لكن هذا سيحذف أيضًا kbase_queue. لذا ، إذا لم يكن ذلك ممكنًا من قائمة الانتظار ، فماذا عن محاولة إلغاء الابتعاد من أ kbase_queue_group؟ على سبيل المثال ، ماذا يحدث إذا أ kbase_queue_group يتم إنهاء مع KBASE_IOCTL_CS_QUEUE_GROUP_TERMINATE ioctl؟ عندما أ kbase_queue_group ينتهي ، كجزء من عملية التنظيف ، يستدعي kbase_csf_term_descheduled_queue_group لإلغاء قوائم الانتظار التي ترتبط بها:
void kbase_csf_term_descheduled_queue_group(struct kbase_queue_group *group)
{
...
for (i = 0; i < max_streams; i++) {
struct kbase_queue *queue = group->bound_queues(i);
/* The group is already being evicted from the scheduler */
if (queue)
unbind_stopped_queue(kctx, queue);
}
...
}هذا ثم يعيد تعيين queue->group مجال kbase_queue هذا ينفجر:
static void unbind_stopped_queue(struct kbase_context *kctx, struct kbase_queue *queue)
{
...
if (queue->bind_state != KBASE_CSF_QUEUE_UNBOUND) {
...
queue->group->bound_queues(queue->csi_index) = NULL;
queue->group = NULL;
...
queue->bind_state = KBASE_CSF_QUEUE_UNBOUND;
}
}على وجه الخصوص ، هذا يسمح الآن kbase_queue لربط آخر kbase_queue_group. هذا يعني أنه يمكنني الآن إنشاء صفحة استخدام صفحة بعد الخطوات التالية:
- إنشاء
kbase_queueوkbase_queue_groupثم ربطkbase_queueإلىkbase_queue_group. - قم بإنشاء صفحات ذاكرة GPU لصفحات المستخدم IO في
kbase_queueورسم خريطة لهم إلى مساحة المستخدم باستخدام أmmapيتصل. ثم يتم تخزين هذه الصفحات فيqueue->physمجالkbase_queue. - إنهاء
kbase_queue_group، والتي تفلت أيضاkbase_queue. - إنشاء آخر
kbase_queue_groupوربطkbase_queueلهذه المجموعة الجديدة. - قم بإنشاء صفحات ذاكرة GPU جديدة لصفحات المستخدم IO في هذا
kbase_queueورسم خريطة لهم إلى مساحة المستخدم. هذه الصفحات الآن تكتب الصفحات الموجودة فيqueue->phys. - قم بإلغاء تأليف ذاكرة مساحة المستخدم التي تم تعيينها في الخطوة 2. هذا يحرر الصفحات في
queue->physويزيل تعيين مساحة المستخدم التي تم إنشاؤها في الخطوة 2. ومع ذلك ، فإن الصفحات التي يتم تحريرها هي الآن صفحات الذاكرة التي تم إنشاؤها وتعيينها في الخطوة 5 ، والتي لا تزال تم تعيينها إلى مساحة المستخدم.
هذا ، على وجه الخصوص ، يعني أنه لا يزال من الممكن الوصول إلى الصفحات التي يتم تحريرها في الخطوة 6 من ما ورد أعلاه من تطبيق المستخدم. باستخدام أ تقنية أنني استخدمت سابقًا ، يمكنني إعادة استخدام هذه الصفحات المحررة أدلة الجدول العالمية (PGD) من GPU مالي.
لتلخيص ، دعونا نلقي نظرة على كيفية دعم صفحات أ kbase_va_region يتم تخصيصها. عند تخصيص صفحات لمتجر الدعم من أ kbase_va_region، ال kbase_mem_pool_alloc_pages يتم استخدام الوظيفة:
int kbase_mem_pool_alloc_pages(struct kbase_mem_pool *pool, size_t nr_4k_pages,
struct tagged_addr *pages, bool partial_allowed)
{
...
/* Get pages from this pool */
while (nr_from_pool--) {
p = kbase_mem_pool_remove_locked(pool); //<------- 1.
...
}
...
if (i != nr_4k_pages && pool->next_pool) {
/* Allocate via next pool */
err = kbase_mem_pool_alloc_pages(pool->next_pool, //<----- 2.
nr_4k_pages - i, pages + i, partial_allowed);
...
} else {
/* Get any remaining pages from kernel */
while (i != nr_4k_pages) {
p = kbase_mem_alloc_page(pool); //<------- 3.
...
}
...
}
...
}حجة الإدخال kbase_mem_pool هو تجمع الذاكرة الذي تديره كائن KBase_Context المرتبط بملف برنامج التشغيل الذي يتم استخدامه لتخصيص ذاكرة GPU. كما تشير التعليقات ، يتم التخصيص فعليًا في المستويات. أولاً سيتم تخصيص الصفحات من التيار kbase_mem_pool استخدام kbase_mem_pool_remove_locked (1 في ما سبق). إذا لم تكن هناك قدرة كافية في التيار kbase_mem_pool لتلبية الطلب ، ثم pool->next_pool، يستخدم لتخصيص الصفحات (2 في ما سبق). إذا حتى pool->next_pool ليس لديه القدرة ، ثم kbase_mem_alloc_page يستخدم لتخصيص الصفحات مباشرة من kernel عبر تخصيص Buddy (تخصيص الصفحة في kernel).
عند تحرير الصفحة ، يحدث الشيء نفسه في الاتجاه المعاكس: kbase_mem_pool_free_pages يحاول أولاً إعادة الصفحات إلى kbase_mem_pool من التيار kbase_context، إذا كان تجمع الذاكرة ممتلئًا ، فسوف يحاول إعادة الصفحات المتبقية إلى pool->next_pool. إذا كان المسبح التالي ممتلئًا أيضًا ، فسيتم إرجاع الصفحات المتبقية إلى النواة عن طريق تحريرها عبر مخصص الأصدقاء.
كما لوحظ في رسالتي “إفساد الذاكرة دون فساد الذاكرة”و pool->next_pool هو تجمع الذاكرة يديره برنامج تشغيل Mali ومشاركته من قبل KBase_Context. كما أنه يستخدم لتخصيص أدلة الجدول العالمية (PGD) تستخدم من قبل سياقات GPU. على وجه الخصوص ، هذا يعني أنه من خلال ترتيب تجمعات الذاكرة بعناية ، من الممكن التسبب في صفحة دعم محررة في أ kbase_va_region ليتم إعادة استخدامها كـ PGD لسياق GPU. ((اقرأ التفاصيل من كيفية تحقيق هذا.)
بمجرد إعادة استخدام الصفحة المحررة كـ PGD لسياق GPU ، يمكن استخدام تعيين مساحة المستخدم لإعادة كتابة PGD من GPU. هذا يسمح بعد ذلك بأي ذاكرة kernel ، بما في ذلك رمز kernel ، لتخطيطها إلى وحدة معالجة الرسومات ، والتي تسمح لي بإعادة كتابة رمز kernel وبالتالي تنفيذ رمز النواة التعسفي. كما يتيح لي قراءة وكتابة بيانات النواة التعسفية ، بحيث يمكنني بسهولة إعادة كتابة بيانات الاعتماد على عمليتي للحصول على الجذر ، وكذلك لتعطيل Selinux.
انظر استغلال Pixel 8 مع بعض ملاحظات الإعداد.
كيف يتجاوز هذا MTE؟
قبل الاختتام ، دعونا نلقي نظرة على سبب تمكن هذا الاستغلال من تجاوز امتداد وضع العلامات على الذاكرة (MTE) – الحماية التي كان ينبغي أن تجعل هذا النوع من الهجوم مستحيلًا.
امتداد وضع علامة الذاكرة (MTE) هو ميزة أمان على معالجات الذراع الأحدث التي تستخدم تطبيقات الأجهزة للتحقق من تعبئة الذاكرة.
تستخدم بنية ARM64 مؤشرات 64 بت للوصول إلى الذاكرة ، بينما تستخدم معظم التطبيقات مساحة عنوان أصغر بكثير (على سبيل المثال ، 39 أو 48 أو 52 بت). أعلى البتات في مؤشر 64 بت غير مستخدمة بالفعل. تتمثل الفكرة الرئيسية في وضع علامة الذاكرة في استخدام هذه البتات العليا في عنوان لتخزين “علامة” يمكن استخدامها للتحقق من العلامة الأخرى المخزنة في كتلة الذاكرة المرتبطة بالعنوان.
عندما يحدث سعة خطي ويتم استخدام مؤشر لإرهاق كتلة ذاكرة مجاورة ، من المحتمل أن تكون العلامة الموجودة على المؤشر مختلفة عن العلامة في كتلة الذاكرة المجاورة. من خلال التحقق من هذه العلامات في وقت dereference ، مثل هذا التناقض ، وبالتالي يمكن اكتشاف dereference التالفة. بالنسبة إلى فساد الذاكرة من النوع الخالي من الاستخدام ، طالما تم مسح العلامة الموجودة في كتلة الذاكرة في كل مرة يتم فيها تحريرها وإعادة تعيين علامة جديدة عند تخصيصها ، فإن إزالة كائن محرّر بالفعل ومستصل عليه سيؤدي أيضًا إلى تباين بين علامة المؤشر والعلامة في الذاكرة ، والتي تتيح اكتشاف الاستخدام المجاني.

امتداد وضع علامة الذاكرة هو مجموعة تعليمية تم تقديمها في الإصدار V8.5A من بنية الذراع ، التي تسرع عملية وضع العلامات والتحقق من الذاكرة مع الأجهزة. هذا يجعل من الممكن استخدام علامة الذاكرة في التطبيقات العملية. في البنية التي تتوفر فيها تعليمات تسارع الأجهزة ، لا يزال هناك حاجة إلى دعم البرامج في مخصص الذاكرة لاستدعاء تعليمات وضع علامة الذاكرة. في kernel Linux ، تخصيص Slub، تستخدم لتخصيص كائنات النواة ، و تخصيص الأصدقاء، تستخدم لتخصيص صفحات الذاكرة ، والدعم لعلامة الذاكرة.
يمكن للقراء المهتمين بمزيد من التفاصيل ، على سبيل المثال ، استشارة هذا المقال و ورقة بيضاء أصدرت بواسطة ARM.
كما ذكرت في المقدمة ، فإن هذا الاستغلال قادر على تجاوز MTE. ومع ذلك ، على عكس أ الضعف السابق التي أبلغت عنها ، حيث يتم الوصول إلى صفحة ذاكرة محررة عبر GPU ، تصل هذه الأخطاء إلى صفحة الذاكرة المحررة عبر تعيين مساحة المستخدم. نظرًا لأن تخصيص الصفحة و dereferencing محمي من قبل MTE ، فربما يكون من المستغرب إلى حد ما أن هذا الخطأ يدير تجاوز MTE. في البداية ، اعتقدت أن هذا يرجع إلى أن صفحة الذاكرة المشاركة في الضعف تتم إدارتها بواسطة kbase_mem_pool، وهو تجمع ذاكرة مخصص يستخدمه برنامج تشغيل GPU Mali. في الاستغلال ، يتم إعادة استخدام صفحة الذاكرة المحررة التي يتم إعادة استخدامها حيث يتم إعادة PGD ببساطة إلى تجمع الذاكرة المدير بواسطة kbase_mem_pool، ثم تخصيص مرة أخرى من تجمع الذاكرة. لذلك لم يتم تحرير الصفحة أبدًا من قبل تخصيص الأصدقاء ، وبالتالي لم يتم حمايتها بواسطة MTE. على الرغم من أن هذا صحيح ، فقد قررت أيضًا محاولة تحرير الصفحة بشكل صحيح وإعادتها إلى تخصيص Buddy. لدهشتي ، لم يتم تشغيل MTE حتى عندما يتم الوصول إلى الصفحة بعد تحريرها من قبل مخصص Buddy. بعد بعض التجارب وقراءة التعليمات البرمجية المصدر ، يبدو أن تعيينات الصفحة التي تم إنشاؤها بواسطة mgm_vmf_insert_pfn_prot في kbase_csf_user_io_pages_vm_fault، والتي تستخدم للوصول إلى صفحة الذاكرة بعد تحريرها ، وتستخدم في النهاية insert_pfn لإنشاء التعيين ، الذي يدرج إطار الصفحة في جدول صفحة مساحة المستخدم. لست متأكدًا تمامًا ، لكن يبدو أنه نظرًا لأن إطارات الصفحة يتم إدخالها مباشرة في جدول صفحة مساحة المستخدم ، فإن الوصول إلى تلك الصفحات من مساحة المستخدم لا يتطلب إزالة مستوى Kernel وبالتالي لا يؤدي إلى MTE.
خاتمة
في هذا المنشور ، أظهرت كيف يمكن استخدام CVE-2025-0072 لاكتساب تنفيذ رمز النواة التعسفي على بكسل 8 مع تمكين kernel MTE. على عكس أ الضعف السابق لقد أبلغت ، والتي تتجاوز MTE عن طريق الوصول إلى الذاكرة المحررة من وحدة معالجة الرسومات ، وتوصل هذه الثغرة الأمنية إلى الذاكرة المحررة عبر تعيين ذاكرة مساحة المستخدم التي يتم إدراجها بواسطة برنامج التشغيل. يوضح هذا أنه يمكن تجاوز MTE أيضًا عند الوصول إلى صفحات الذاكرة المحررة عبر تعيينات الذاكرة في مساحة المستخدم ، وهو سيناريو أكثر شيوعًا من الضعف السابق.
كتبه

اترك تعليقاً