
بعد العرض التقديمي لعام 2025 ، كيف تجد Nvidia نجاحًا كبيرًا مع Vulkan للتعلم الآلي / الآلة ومنافسة بالفعل لـ CUDA في بعض المناطق ، بدأ Red Hat Engineer و DRM Subsyster Pustainer David Airlie في استكشاف إمكانات سائقي Mesa Vulkan لاستدلال الذكاء الاصطناعي. لقد نجح في استخدام برامج تشغيل Intel ANV و NVIDIA NVK و Radeon RADV لاستدلال AI القائم على Vulkan ، بينما يتم اختبار أجهزة Radeon التي تم اختبارها في المكان الذي يظهر فيه أكثر (الأداء) في الوقت الحالي ، وحتى التنافس مع مكدس ROCM Compute.
شارك David Airlie منشورًا في المدونة اليوم يحدد تجاربه لاستكشاف سائقي Mesa Vulkan لاستدلال الذكاء الاصطناعي. في الوقت نفسه ، يعمل هو وآخرون مثل Karol Herbst of Red Hat على معالجة فجوات الميزات في سائقي Mesa Vulkan لجعل ذلك أكثر ملاءمة للتعامل مع أعباء عمل الذكاء الاصطناعي.
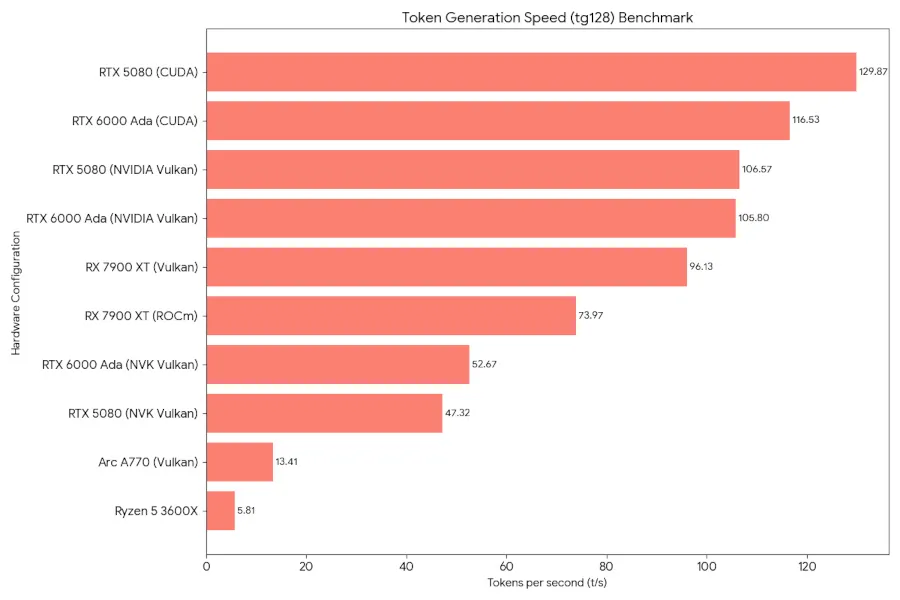
باستخدام Wrapper Ramalama to llama.cpp ، تم اختبار Airlie خيارات سائق مختلفة مفتوحة المصدر ومغلقة. مع برنامج تشغيل Mesa NVK ، لا يزال الأداء أبطأ بكثير من مكدس السائق الرسمي Nvidia المغلقة. لا مفاجأة حقيقية ، خاصة بالنظر إلى معايير رسومات NVK الأخيرة في MESA 25.2 NVK مقابل NVIDIA R575 Linux Graphics Performance for Geforce RTX 40 Series.
على جانب Intel ، تمكن من الحصول على استنتاج Vulkan AI يعمل مع سائق ANV ولكنه غير قادر على عمل مكدس Oneapi/Sycl بشكل جيد. على جانب AMD هو المكان الذي يظهر فيه حاليًا الأكثر إمكانات. تظهر نتائج Airlie أن أداء Radv Vulkan مع Ramalama/Llama.cpp للجيل الرمزي يمكن أن يكون أسرع من استخدام مكدس AMD ROCM الرسمي. من خلال المعالجة السريعة هي المكان الذي تقدم فيه ROCM إلى الأمام ، على الأقل في الوقت الحالي ، ولكن هناك أمل في أن بعض تحسينات MESA/RADV يمكن أن تضعها قبل ROCM.
فيما يلي البيانات المشتركة من Airlie بمقارنة برنامج تشغيل/أجهزة GPU:
اقرأ المزيد عن مغامرته المقارنة من AI Vulkan مدونته. سيكون من المثير للاهتمام تشغيل بعض المعايير على جانبنا بمجرد أن ينضج سائقو Mesa Vulkan بشكل أكبر لأعباء عمل الذكاء الاصطناعي.
اترك تعليقاً